一、引言
公共机构作为全社会的重要组成部分,在实现碳中和与碳达峰目标方面发挥着至关重要的作用。根据国家统计局网站公开数据及国管局公开数据显示,2023年全国能源消费总量57.2亿吨标准煤,其中公共机构能源消费总量为1.65亿吨标准煤,占比3%。用电量作为公共机构能源资源消费总量的重要组成部分,对其进行深入研究具有重要意义。通过预测公共机构用电量,可以及时发现公共机构用电量未来增长(下降)趋势,进一步推测公共机构能源资源消耗的未来趋势,为制定和调整节能政策及措施提供科学依据。
二、公共机构能源资源消费数据统计分析发展现状
随着信息化技术的不断发展,公共机构能源资源数据统计分析已经逐渐成为一项重要的任务。目前,我国公共机构节能降耗的相关研究工作主要有4个方面:一是从能源的消耗方面入手,目前主流的方向是建筑的节能;二是从能源结构方面入手,主要提倡大力发展绿色节能减排;三是从能源的使用方式和意识方面入手,培养人们的节能意识和习惯;四是从公共机构能耗定额方面入手,为公共机构节能管控定额定量,引导公共机构从定额指标方面节能减排,而公共能耗数据分析与挖掘还需进一步发展。
三、时间序列模型相关理论
时间序列分析是一种统计分析方法,用于研究数据随时间变化的规律和趋势。它通过对按照时间顺序排列的一系列数据点进行建模、预测和分析,揭示数据背后的模式、趋势和周期性,并基于这些模式和趋势对未来进行预测,为管理者决策提供理论科学依据。
处理单时间序列的时间序列模型一般分为:自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)、累计式自回归移动平均模型(ARIMA)等。
在自回归表达式中,只要有限个权数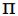 非0,则该时间序列过程被称为p阶自回归模型,表示为AR(p)。自回归模型可用来描述时间序列当前值由其滞后期加上随机数所决定的情景,如公式(3-1)所示。
非0,则该时间序列过程被称为p阶自回归模型,表示为AR(p)。自回归模型可用来描述时间序列当前值由其滞后期加上随机数所决定的情景,如公式(3-1)所示。
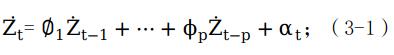
在移动平均表达式中,只要有限个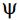 权非零,那么得到的过程被称为q阶移动平均模型,表示为MA(q)。移动平均模型常用于描述事件产生只持续短时间的即时效应,如公式(3-2)所示。
权非零,那么得到的过程被称为q阶移动平均模型,表示为MA(q)。移动平均模型常用于描述事件产生只持续短时间的即时效应,如公式(3-2)所示。
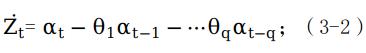
自回归移动平均模型(ARMA)是一种常用的时间序列分析方法,用于描述时间序列数据中存在的自回归(AR)和移动平均(MA)成分。这些成分反映了时间序列数据中的统计特性,如自相关性和随机性。在没有季节性因素的情况下,时间序列数据的变化主要受自回归和移动平均因素的影响,因此可表示为混合的ARMA(p,q),如公式(3-3)所示。
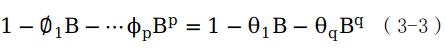
累计式回归移动平均模型(ARIMA)是一种包含自回归(AR)、移动平均(MA)和差分(I)成分的模型,可以用于处理具有季节性因素或不平稳的时间序列数据。在现实应用中,时间序列数据通常是非平稳的,即其均值和或方差会随时间发生变化。ARIMA模型通过对数据进行差分,将时间序列数据分解为季节性成分、趋势成分和随机波动成分,把非平稳时间序列转换为平稳时间序列,更好地描述数据的统计特性,从而可以对其进行有效建模。ARIMA模型的基本原理可以用公式(3-4)表示:
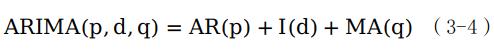
其中,AR(p)表示自回归模型,I(d)表示差分模型,MA(q)表示移动平均模型。ARIMA(p,d,q)公式可表示为(3-5)。
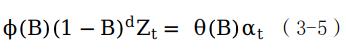
其中,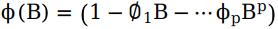 ,
,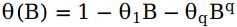 ,序列
,序列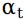 是服从N(0,
是服从N(0,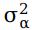 )分布的高斯白噪声过程。
)分布的高斯白噪声过程。
四、BP神经网络相关理论
BP网络模型,即反向传播神经网络模型,是一种通过学习和优化神经网络结构,以实现输入输出映射关系的神经网络模型。它通过反向传播算法不断调整神经网络的权重和偏置,使得神经网络的输出能够尽可能地接近实际输出,从而实现对输入数据的分类、预测等任务。
BP网络模型主要由输入层、隐藏层和输出层组成,每一层之间使用权重连接,隐藏层和输出层之间通过阈值进行连接。BP网络模型通过正向传播和反向传播两个过程来学习权重和阈值。在正向传播过程中,输入数据通过隐藏层逐层处理,最终得到输出结果;在反向传播过程中,根据实际输出与期望输出的误差来调整权重和阈值,从而减小误差。
输入层向量由n个神经元节点构成,常用x表示,即输入向量为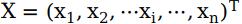 ;隐藏层向量由p个神经元节点构成,常用z表示,即隐藏层向量为
;隐藏层向量由p个神经元节点构成,常用z表示,即隐藏层向量为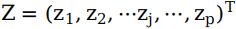 ;输出层向量由m个神经元节点构成,常用y表示,即输出向量为
;输出层向量由m个神经元节点构成,常用y表示,即输出向量为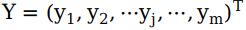 。
。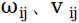 表示连接各层神经元之间的权值。
表示连接各层神经元之间的权值。
隐藏层第j个节点的输出如公式(4-1)所示。
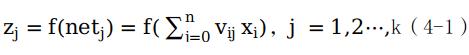
输出层第m个节点的输出如公式(4-2)所示。
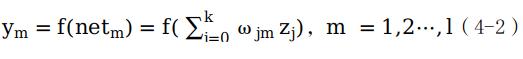
五、预测模型构建与修正
针对公共机构能耗数据,如果通过绘图发现季节性影响因素明显或数据不平稳,则采取累计式自回归移动平均模型(ARIMA)更具有实际应用意义;在没有季节性因素或数据平稳的情况下,可以使用(ARMA)模型进行预测。
根据研究显示,公共机构能源资源消耗量也会受到其他因素的影响,诸如天气、季节、节假日与工作日等影响,神经网络对复杂非线性具有拟合能力,因此可以采用BP神经网络对时间序列模型(自回归移动平均模型ARMA或累计式自回归移动平均模型ARIMA)进行修正,使预测模型更具科学性和适用性。
因此本文将能耗数据预测模型分为两个阶段,即时间序列预测模型构建阶段和时间序列模型修正阶段。
模型预测阶段,根据公共机构时间序列数据图及检验结果,确定数据平稳性。若时间序列数据平稳且非白噪声,则根据ACF和PACF图像及AIC准则和BIC准则确定阶数;若时间序列数据不平稳,则考虑利用差分方式处理数据,数据平稳后确定阶数,进行模型拟合,并预测未来数据值。
模型修正阶段,神经系统输入的神经元为时间序列预测模型的预测结果、天气情况、工作日、用能人数、建筑面积等因素,输出层为修正后的预测结果。现阶段BP神经网络模型一般采用3层网络结构,即输入层、隐藏层、输出层。
六、算例验证——以第三产业用电量为例
根据国务院办公厅转发的国家统计局关于建立第三产业统计报告上对中国三次产业划分的意见,国家机关、政党机关、社会团体、警察、军队等属于第三产业。因此本文选取国家统计局公开发布的1978—2009年第三产业用电量数据作为算例数据,采用R语言搭建基于时间序列的预测模型,预测2010—2022年用电量数据,并利用Matlab搭建BP神经网络模型将时间序列预测数据进行修正,对比时间序列预测值与BP神经网络模型修正值相较实际值误差率的大小。整个预测修正模型分为两个阶段,即预测阶段和修正阶段。
(一)时间序列的建立与数据预测
通过整理1978—2009年第三产业用电量数据,共得到32个样本点,构成第三产业年用电量时序图,如图1所示。
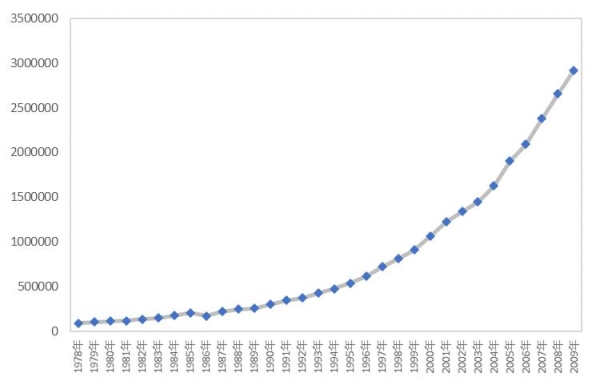
图1 第三产业用电量1978—2009年用电量时序图

图2 第三产业用电量1978—2009年用电量KPSS检验结果
根据图1显示,第三产业用电量并没有呈现出明显的季节特征,但存在明显上升趋势,采用KPSS法进行平稳性检验,检验时间序列的平稳性。检验结果如图2所示,统计量值小于临界值,因此序列存在单位根,1978—2009年第三产业用电量为一组非平稳的时间序列。本文中将数据进行二阶差分处理,差分后如图3所示,处理后为平稳的时间序列数据。LB白噪声检验结果如图4所示,统计量值小于显著性水平(0.05),因此该序列为显著非白噪声时间序列。
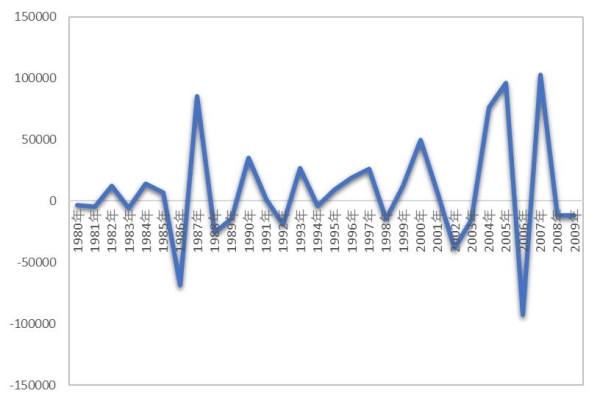
图3 第三产业用电量1978—2009年用电量二阶差分图

图4 第三产业用电量1978—2009年用电量白噪声检验结果
如图5和6所示,ACF为拖尾与PACF均表现为截尾,ACF阶数为1或2,PACF阶数明显表现为2。
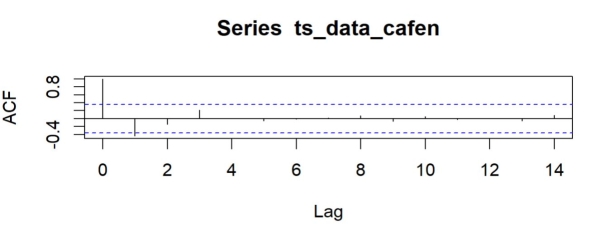
图5 ACF图
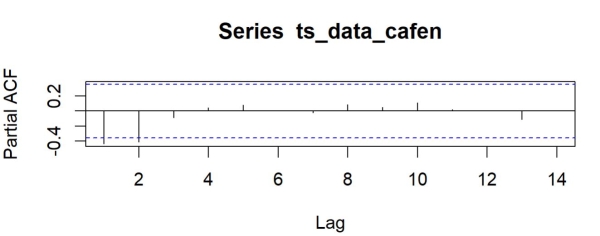
图6 PACF图
根据AIC准则函数值和BIC准则函数值最终确定最优模型阶数。并选取累计式自回归移动平均模型(ARIMA)模型,进行拟合预测。预测结果及误差率如图7所示。
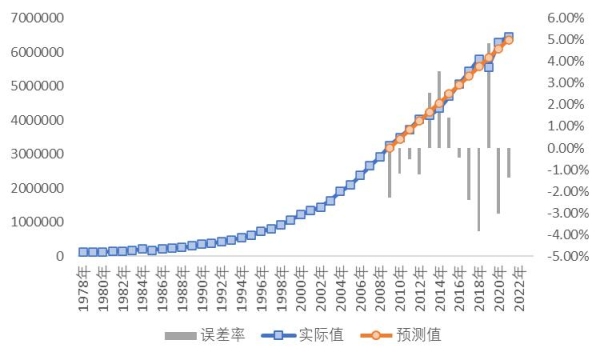
图7 ARIMA预测值
(二)BP神经网络修正
由于本文选取算例数据为年数据,因此并不存在节假日和工作日的区别。根据研究表明,实际用电量与天气条件有密切的关系,尤其是对温度的变化最为敏感,与相对湿度、风和日照时数、降水也有一定的相关性。因此本文主要以天气条件为主要衡量指标,对时间序列模型预测结果进行修正。
根据Kolmogotov定理,在一定条件下,一个三层神经网络可以以任意精度去模拟任意的映射关系。通过众多实验数据发现,包含两个以上隐含层的神经网络的训练在预测的准确率方面并不比一个隐含层的神经网络高,因此采取三层BP神经网络进行修正。
本文选取国家气象局公开发布的2010—2022年全年降雨量(毫米)、平均气温、日照时数为天气衡量指标、结合ARIMA模型预测结果,作为输入层。修正后的预测结果作为输出层。由于BP神经网络隐藏层节点数并没有标准定理,现有的BP神经网络模型隐藏节点数大部分选取训练结果较好的节点数,根据Hecht Nielsen在1987年对单个隐含层的神经网络进行讨论和研究结论表明隐含层节点数应为:2N+1,N为输入层节点个数。通过训练及验证,因此本文隐藏层节点数为9。
图8 归一化前指标分布数量集
图9 归一化后指标分布数量集
根据图8所示,未归一化的指标呈现数量级差异,时间序列预测指标与天气条件衡量指标数据相差较大,因此输入层4个神经元指标进行归一化处理,处理后数据指标差异情况如图9所示。
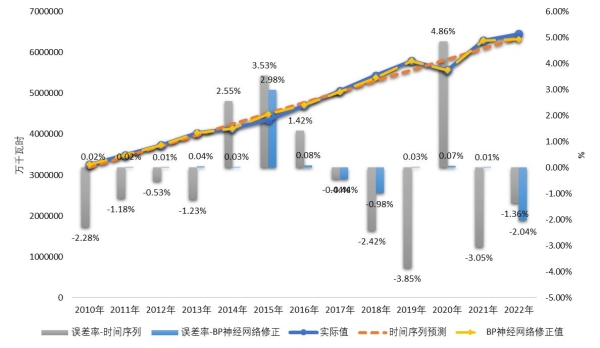
图10 第三产业用电量修正模型误差比较
BP神经网络修正结果如图10和表1所示。从表1可以看出,BP神经网络修正后的预测结果满足要求的准确精度,修正后的平均误差优于单一ARIMA模型预测的平均误差,BP神经网络修正后的结果优于单一ARIMA模型预测结果。BP神经网络修正后的预测结果误差率多围绕0点上下浮动,变化范围在-2.04%—3%之间,优于单一ARIMA模型的预测结果。
表1 第三产业用电量修正模型误差比较
|
年份 |
实际值 |
时间序列预测值 |
误差率(时间序列) |
BP神经网络修正值 |
误差率(BP神经网络修正) |
|
2010年 |
3258009 |
3183572 |
-2.28% |
3258575.63 |
0.02% |
|
2011年 |
3490143 |
3448915 |
-1.18% |
3490750.93 |
0.02% |
|
2012年 |
3734022 |
3714258 |
-0.53% |
3734341.20 |
0.01% |
|
2013年 |
4029145 |
3979601 |
-1.23% |
4030889.50 |
0.04% |
|
2014年 |
4139319 |
4244944 |
2.55% |
4140586.97 |
0.03% |
|
2015年 |
4356332 |
4510287 |
3.53% |
4486310.07 |
2.98% |
|
2016年 |
4708959 |
4775630 |
1.42% |
4712777.81 |
0.08% |
|
2017年 |
5063019 |
5040973 |
-0.44% |
5040712.93 |
-0.44% |
|
2018年 |
5437818 |
5306316 |
-2.42% |
5384475.30 |
-0.98% |
|
2019年 |
5794810 |
5571659 |
-3.85% |
5796363.42 |
0.03% |
|
2020年 |
5566552 |
5837002 |
4.86% |
5570370.35 |
0.07% |
|
2021年 |
6294023 |
6102345 |
-3.05% |
6294440.41 |
0.01% |
|
2022年 |
6455725 |
6367688 |
-1.36% |
6323990.63 |
-2.04% |
七、结论
如今的公共机构能源资源消费数据应用与分析多数停留在描述统计阶段;公共机构计量器具日渐完备的背景下,挖掘公共机构能源资源数据潜力、分析能源资源消费影响要素、提升公共机构能耗预测能力,对公共机构节能工作的开展与优化管理起着重要作用。
本文以第三产业用电量为算例,首先采用时间序列分析法进行预测,后引用温度、日照时数、降水量为天气指标,对时间序列预测结果进行修正,得到精度较高的组合预测模型,获取更具实际意义的用电量预测值,进一步验证了该组合模型的可行性。
根据目前的研究工作表明,此模型对于公共机构用电量预测是具有实际应用价值的。未来针对公共机构用电量预测值修正阶段,BP网络模型输入神经元环节,可以增加用能人数、建筑面积等影响因素,也可将能耗颗粒度精确到月份,预测结果的准确性将进一步提高。若该模型拟合公共机构能耗预测,即水、电、燃气等能耗预测,BP网络模型输入神经元可根据不同用能特点,更改输入神经元,以得到更精确的预测值。
八、公共机构能源资源数据预测建议
公共机构的能耗预测未来发展需要依靠先进的数据分析技术和智能化管理系统,提高数据挖掘能力和数据分析预测能力,以达成共同推动节能减排、提高能源利用效率的目标的实现。
数据整合与共享:各机关事务管理局充分应用国管局信息化平台整合各类能源数据。通过整合和共享数据,公共机构可以更全面地了解能源消耗情况,从而更准确地预测未来的能耗趋势。
智能化数据分析:利用最新的数据分析技术,如人工智能和机器学习,对能源数据进行深度分析。这些技术可以帮助公共机构发现能源消耗中的模式和趋势,从而更有效地预测未来的能耗。
预测模型的应用:建立基于历史和实时数据的能耗预测模型。这些模型可以根据公共机构的实际情况,预测未来的能耗趋势,为公共机构的能源管理提供重要的参考信息。
能源管理系统的升级:升级现有的能源管理系统,使其能够更好地支持能耗预测。这包括引入新的技术工具和软件,优化能源管理流程,提高能源管理的效率和准确性。
作者:何璇
作者单位:北京市机关事务管理局
本文获2024年研究成果鉴定一等奖


